Update: Check out our latest on DIA here.
MORE THAN 5000 PROTEINS IDENTIFIED – 200 TIMES A DAY
Proteomics is a field in continuous development, where robust and optimized processes throughout the entire workflow – from sample preparation to acquisition strategies and downstream data processing are the goal. In recent years, data independent workflows have gained increased interest due to its high degree of reproducibility, better sensitivity and accuracy for quantification compared to classic data-dependent workflows.
Active developments in DIA acquisition strategies have moved the field further in the past years, latest with the development of diaPASEF, which utilizes the trapped ion mobility separation (TIMS) on the Bruker timsTOF Pro mass spectrometer. Most importantly, diaPASEF yields 2-5x improvement in sensitivity and thus increasing the effective duty cycle. To gain biological insight from the increased sensitivity, the introduction of neural-network based processing of raw data, have been a game-changer in the last couple of years.
HIGH SENSITIVITY DIAPASEF PROTEOMICS WITH DIA-NN AND FRAGPIPE
A collaboration between the Ralser group at the Crick Institute, UK and the Nesvizhskii group at University of Michigan, USA introduce the latest addition to the DIA-NN software, which was originally conceived to maximize the performance of fast proteomics experiments. They have developed a neural network-based ion mobility module, which they benchmark the performance of in combination with FragPipe-generated libraries. They reprocessed the diaPASEF reference dataset (read more about diaPASEF with Evosep One here), where 200 ng of HeLa peptides were analyzed in triplicates with the 60, 100 and 200 samples per day methods.
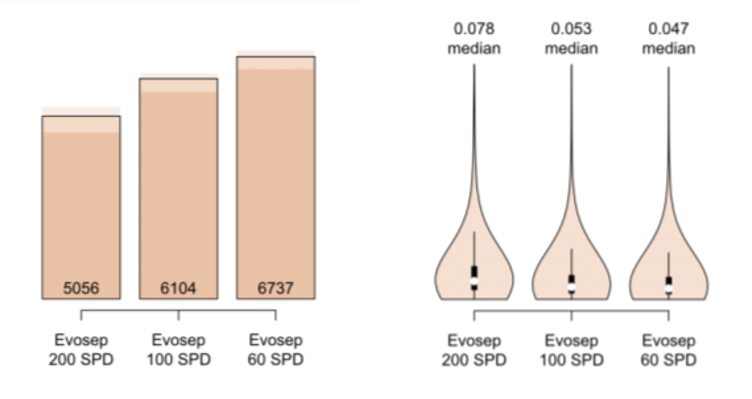
They built a spectral library with FragPipe from 24 ddaPASEF runs containing 8201 proteins. Using this library, DIA-NN quantified on average 5056 proteins from 200ng HeLa digest analyzed with the ultra fast 200 SPD Evosep One method. Notably, they obtained very high data completeness of 94%. By extending the gradient time with the 100 and 60 SPD methods, the proteomic depth increased to 6104 and 6737 proteins respectively. The median CV were below 8% for all three methods.
THE FUTURE OF PROTEOMICS WITH FAST CHROMATOGRAPHIC GRADIENTS
This paper nicely demonstrates the hidden potential of fast gradients, utilized by continued instrument developments focused on sensitive and faster scanning and improved sensitivity in data analysis. With a depth of more than 5000 proteins identified routinely 200 times a day, we are facing possibilities of applying these super-fast gradients for discovery proteomics with large cohorts of clinical samples.
→ Read full publication on biorxiv
→ For a full overview of publications published using the Evosep One Technology visit our Literature room
LET’S STAY IN TOUCH
Join our monthly newsletter to stay tuned on new data and publications using Evosep One technology.
